
For a few people, this will be a very “current problem”, for other, that have suffered through years of “unstable” NAS and Job Queue for that matter .. this upcoming blogpost might be interesting.
The primary reason for this post is an issue that – after quite some debugging – seemed to be an issue introduced in version 17.4 (and currently also v18.0). But I decided to tackle the issue in a way it’s a bit more generic to deal with “unstable Job Queues” in stead of “just this particular issue”.
Disappearing Job Queue Entries
Although this post isn’t just about this current bug that haunts us in this current release of Business Central (17.6 / 18.0 at the time of writing) – I do want to start with that first, though. It has to do with Job Queue Entries that were disappearing for no apparent reason. I traced it down to this code change in the default app.
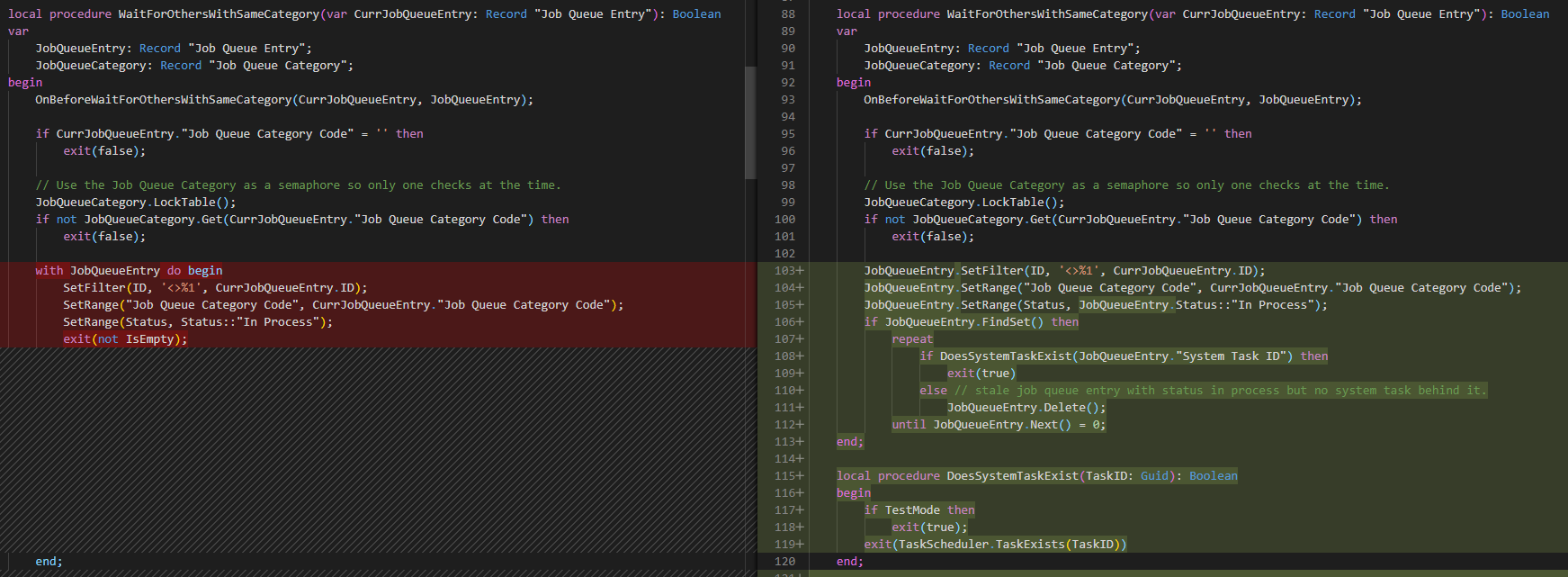
In a way: it happened quite frequently (multiple times a day) that recurring job queue entries were disappearing .. which obviously prevents the execution of the task at hand.
There are some prerequisites to this behavior, though. And you can read them actually quite easily in code:
- They must be part of an existing Job Queue Category
- There must be multiple Job Queue Entries within that category
- It must be a stale job, which means:
- It must be “In Process”
- Although it shouldn’t have an “active” TaskId (which kind of means, that it shouldn’t exist in the Task Scheduler tables).
That’s a lot of “ifs”. But .. in our case .. it happened. Frequently. We use categories to execute jobs in sequence and prevent locking or deadlocks.
Good for us, the issue is solved already in vNext (Minor). This is going to be the new version of the code:
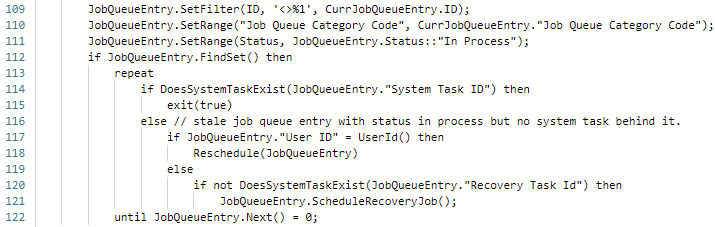
But ..
This also tells us something else. I mean .. Microsoft is writing code to act on certain situations which means that these situations are expected to happen:
- Task Scheduler might “lose” the Task Id that it created for a certain Job Queue Entry
- When a Job Queue is InProcess, it might happen that it “just stops executing”
Or in other words: the Job Queue can act unstable out-of-the-box, and Microsoft is trying to mitigate it in code.
There are a few good reasons why the Job Queue can act somewhat unstable
Before you might go into hate-and-rant-mode – let me try to get you to understand why it’s somewhat expectable that these background stuff might act the way it does. Just imagine:
- Reconfigure / restart a server instance – may be while executing a job
- Installing an app with different code for the job queue to be executed – may be while executing a job
- Upgrade-process
- Kicking a user – may be while executing a job
- …
Some of which we already noticed some instability just after any of these actions. And probably, there are many more.
So, yeah .. It might happen that queues are stopped .. or may be frozen. Let’s accept it – and be happy that Microsoft is at least trying to mitigate it. I’m sure the code in vNext is for sure a (big) step forward.
But .. may be there are things that we can do ourselves as well.
Prevent the delete
As said, above issue might delete Job Queue Entries. If you don’t want to change too much of your settings (like remove all categories until Microsoft fixed the issue) to prevent this, you might also simply prevent the delete. How you can do that? Well – just subscribe to the OnBeforeDeleteEvent of the “job Queue Entry” table ;-). Here is an example:

But .. as said – this only solves this one issue that is current – but we can do more… and may be even look somewhat in the future and make the Job Queue act more stable for our customers …
Restart just in case
One thing we learned is that restarting a job queue never hurts. Although “never” isn’t really the right word to use here, because restarting may come with its caveats.. . But we’ll come to that.
We noticed that we wanted to be able to restart job queues from outside the web client – in fact – from PowerShell (Duh… 😜). Thing is, restarting a Job Queue Entry is actually done in the client by setting and resetting the status by simply calling the “Restart” method on the “Job Queue Entry” table.
If we decouple this a little bit .. I decided to divide the problem in two parts:
– We need to be able to run “any stuff” in BC from PowerShell
– We need to be able to extend this “any stuff” any time we need
Restart Job Queues – triggered from an API
I decided to implement some kind of generic event, which would be raised by a simple API call .. which would kind of “discover and run” the business logic that was subscribed to it.
So, I simply created two publishers
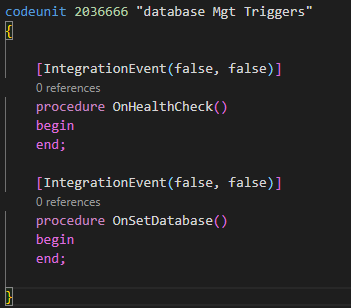
And trigger it from this “dirty workaround” API 😜 (I actually don’t need data, just the function call from the API).
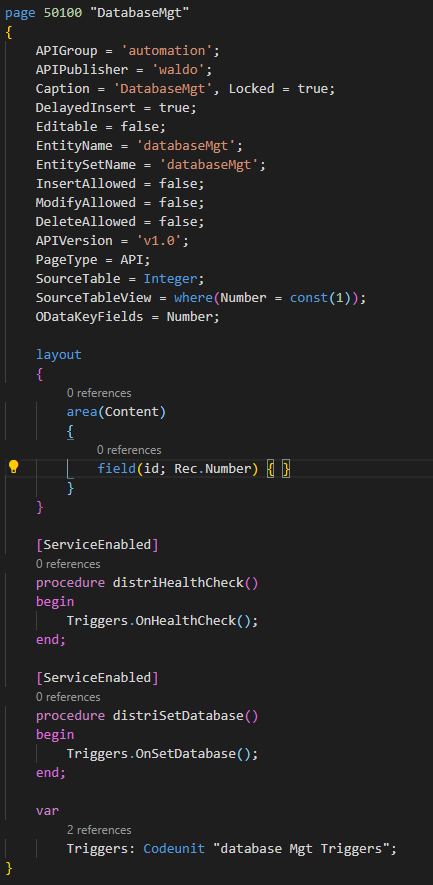
As a second step, I simply subscribe my Job Queue Restart functionality.

So now, we can restart job queue entries in an automated way.

When do we restart?
We decided to restart at every single app deploy (so, basically from our build pipeline) and at restart of services (if any). Because:
– It doesn’t hurt
– It also covers the upgrade-part
– It would also call extra “OnSetDatabase” code that might have been set up in the new version of the app
Language/Region might be changed
One caveat with an automated restart like that would be that the user that does the restart – in our case, the (service) user that runs the DevOps agent – will be configured as the user that executes the jobs. What this might have as a consequence is that the language and/or region might have changed as well. And THAT was a serious issue in our case, because all of a sudden, dates were printed with US format (mm/dd/yy) in stead of BE format (dd/mm/yy). You can imagine that for due dates (and other, like shipment dates), this is not really a good thing to happen.
Long story short, this is because there is a field on the “Scheduled Task” that is leading which format the system will use in that background task. That field is “User Format ID” (don’t ask how long it took for me to find out…).
So, we decided to override this value whenever a JobQueueEntry is being enqueued … .
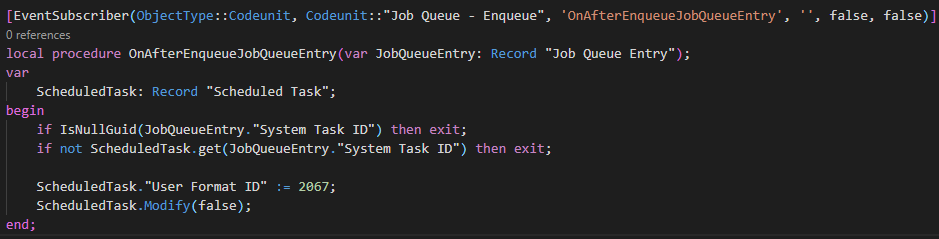
You see a hardcoded value – we didn’t literally do it like this – it’s merely to illustrate you can override the language/region on the background task ;-).
Combine when possible
I don’t know that you know, but you can “Clean Up Data with Retention Policies” – Business Central | Microsoft Docs
A big advantage of this functionality is that all your jobs to clean data from your own Log tables, can be hooked into this functionality – and you basically only have one job in the Job Queue entries that manages all these cleanups. Only one job for many cleanups.
My recommendation would be to apply this kind of “combining” jobs whenever possible and whenever it makes sense. 5 jobs have less chance to fail than 50.
We were able to reduce the amount of Job Queue entries by simply call multiple codeunits within yet a new codeunit – and use that new codeunit for the Job Queue ;-). Sure, it might fail in codeunit 3 and not call codeunit 4 for that matter – so please only combine when it makes sense, and it doesn’t hurt the stability of your own business logic.

Manage your retries
Just a small, obvious (but often forgotten) tip to end with.
Depending on the actual tasks that are executing – it might happen that things go wrong. That’s the simple truth. If you are for example calling an API in your task, it might happen that for a small amount of time, there is no authentication service, because the domain controller is updating .. or there is no connection, because some router is being restarted. And in SaaS, similar small problems can occur to any 3rd party service as well …
It is important to think about these two fields:
- Maximum No. of Attempts to Run – make sure there are enough attempts. We always take 5
- Rerun Delay (sec.) – make sure there is enough time between two attempts.
It doesn’t make sense to try 3 times in 3 seconds, if you know what I mean. For example, a server restart, or a router restart will take more than 3 seconds.
I would advice to make sure there are 15 minutes of retry-window: 5 retries, 180 seconds delay. This has a massive impact in stability, I promise you ;-).
Conclusion
Let’s not expect that the Job Queue will run stable all the time, everytime, out-of-the-box. There are things we can do. Some are small (settings), some involve somewhat more work. I hope this helped you at least a little bit to think about things you could do.
9 comments
3 pings
Skip to comment form
Great post!! Language/Region might be changed was something I was pulling my hair out over for some time now!
Author
Thanks :-). We’re two of only a few .. finally someone that also had this issue :-).
Hope this helps!
I also have this issue and introduced quickfix with a subscriber.
From my investigations I deducted that TaskScheduler.TaskExists() is checking App Database [$ndo$taskscheduling] table and, when the task goes into In Progress state, doesn’t find it anymore. It is a platform level function so my only guess is that it is not taking into account In Progress state (I think state 3). You can check this my adding TaskScheduler.TaskExists() as a column to Job Queue Entries Page.
I also was frustrated – how can someone consider deleting a Recurring Job Queue Entry?? We will see how the new version of code is handling this..
Thanks!
Author
Thanks for your additional info.
Yeah – it beats me too ..
onPrem I use SQL Job that monitors Job Queues Last Heartbeat.
Author
So .. also “outside BC” – makes sense ;-).
What do you do when the heartbeat is .. dead?
I’m restarting Job Queue. Actually with your API I could automate process.
This is very helpful but what about SaaS? How do we restart job queues post deploy when you can’t use PowerShell?
Great post as always! Inspired by this we have setup an API which restarts the job queue entries.
Only problem is when it restarts the entries, then it uses the logged in user. We would like it to restart using the same user as the job queue entry was create by. Do you know of a way to cheat a little, so keep that user and not have it change to the user who calls the restart API?
[…] Stabilize your Job Queue – a few tricks […]
[…] Source : Waldo’s Blog Read more… […]
[…] Stabilize your Job Queue – a few tricks […]