
Remember this post? Probably not. Nearly a year ago at Directions US, I showed some “how did I do stuff” during a number of sessions. And it ended with a lot of feedback, which came down to: “can I have it”? So, that’s where I wrote a post “I have work to do” ;-).
The “DevOps”-part of the work is done: ALOps is available and well used :-).
But the second promise – the “Dependency Analysis”, I only completed in November 2019 – and totally forgot to blog about it. In my defense – I did explain it at NAVTechDays, and that video IS online. You can find it here: NAV TechDays 2019 – Development Methodologies for the future (This is a link to the point in the video that explains the “dependency analysis” part).
What is it all about?
Well, in the move from C/AL to AL, you have a few options.
In short:
either you migrate your old code to AL (you know, the txt2al-way of doing things) and basically end up with “old wine in new bottles”.
Or you rewrite. And if you rewrite, you either rewrite everything in just one app, or you take the opportunity and divide your old monolith into a multitude of apps.
In my opinion, it does make sense to rewrite the solution/product into AL, and take the opportunity to split it in multiple apps – and make dependencies if necessary.
Thing is – when you have a product that multiple people have been working on, for multiple years – there is not one single person that have a overall overview of all created functionalities – let alone how they were developed (and therefore dependent from each other). But – if you are rewriting your product, you probably WANT to have a complete overview of all this, INCLUDING a view on the dependency.
So you have to analyse that. Hence the name: “Dependency Analysis“.
How do I analyze an old codebase, and still have a complete overview of the entire functionality – and how do I decide on how to split it in apps?
In my opinion, the only way to do that, is to automate the crap out of it. The only way to not forget anything, is to not use your memory.
Overview
In my company, we created a set of tools that I’d like to share with you. It contains:
- PowerShell scripts that analyzes the C/AL code
- A Business Central App that has an API to upload the data from PowerShell, and handle it for your analysis
All code is saved in GitHub, and you can find it here: https://github.com/waldo1001/ALDependencyAnalysis
All contributions are very welcome ;-).
Flow
On how to use it, I’d like to refer you to the video, of course – it will get you started in 20 minutes, and explain you the basic steps. In fact, the past couple of months, I referred a few partners to this video, and they were all able to do their dependency analysis – so I guess it’s descriptive enough, and the tools work (well enough ;-)). But still, let me give you a short overview of the steps I think you should take – with a few remarks I think are interesting to consider.
Step 0a: Set up waldo.model.tools
You might remember this blogpost: C/AL Source Code Analysis with PowerShell. Well, it’s that tool we will be using for the next steps. It can analyze C/AL code – so it’s right what we need ;-). And apparently people are able to get it running. I actually came across this blogpost where Ricardo Paiva Moinhos used this tool to create a generic datamigration script from C/AL to AL. Awesome!
Step 0b: Set up a Business Central environment with the ALDependencyAnalysis app
This is actually as simple as cloning the app from the ALDependencyAnalysis-repo, and publish it to the environment where you would like to perform the analysis. In my case, a simple docker container on my laptop. Make sure APIs are available .. because the app will deploy some custom APIs for us to be able to upload data.
When you installed the app, you’ll have a new rolecenter: the “Dependency Analysis Rolecenter“.
Welcome to your “Dependency Analysis Control Center” ;-).
Step 1: Get all objects from C/AL and automatically tag it if possible
The assumption here is that you have exported all objects to C/AL (ALL, also default objects, because most likely, you did changes in these, and you’d want to have the references on where you did changes).
With the waldo.model.tools, you can analyze the C/AL Code – so we’ll use that. In the Scripts-folder of the ALDependencyAnalysis-repo, you’ll find the scripts that I used to upload the necessary stuff to perform the analysis.
So for uploading the objects, you need to run the “prepare” script first to load the objects in PowerShell. You’ll see that the scripts loads the model in the $Model variable, which will be used for the magic. That variable will be quite big in memory ;-). The prepare-script is also going to load all companies from your API – because it needs that in the upcoming scripts.
Next, there is the 1_UploadObjects.ps1 script, that is simply going to loop all objects from the $Model variable, and upload them via the API to your Business Central environment.
Module tagging
It is quite important that during the module, that you tag your object. In a way, your object needs to have a “reason to exist”. An “intent”. A – let’s call it – a “module”. This module-code usually is a piece of business logic that you added to the solution. “FA” could be a module name for “Fixed Assets”, for example. In this example, you see what I mean – all objects get a module (last column): the reason why they were created.
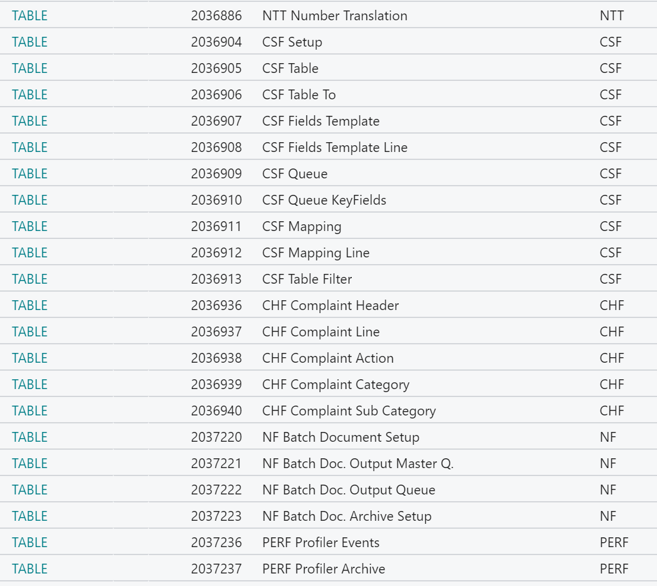
You can imagine that doing this manually, it’s huge job. But probably you have some logic that can determine quite a lot of the object modules for you, like the prefix of an object, the range, or something like that. So we created a function in “ModelObject.Codeunit.al” that can handle that for you. Just change in what you think works best for you!
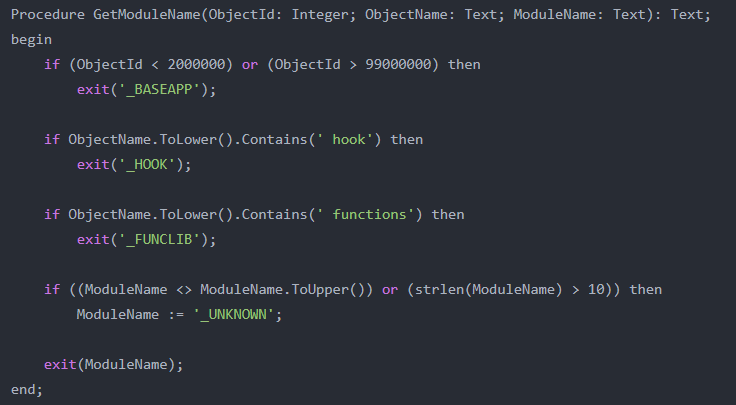
Step 2: Manually correct/ignore modules
From the time you have all objects in the table of your app, it’s time to correct all modules so that every single object in that table is tagged by the right module. Your procedure might not have been able to decently tag all objects, and further on in the analysis, it’s important to have the right names for all objects.
This is also where you would like to ignore the useless modules. Just imagine you already know which parts of your product you will skip .. then it makes no sense to take it further in your analysis.
Step 3: Get Where-Used per object
This is where it gets interesting (or at least in my opinion ;-)).
The idea is that we are going to create dependencies between these modules. Now, do know this:
- We are able to analyze code, including things like “where used”
- This information can be looped and saved (like we did with objects)
- We tagged all objects with a module
So basically, we can find out which modules “use” or are “used by” other modules. And – in an dependency analysis, that information is gold!
So – you can already imagine, there is another script in the Scripts-folder: 2_UploadObjectLinks.ps1. That script is a slightly bit more complicated. It will figure out all links, remove the ones that refer to themselves, build an object collection, loop it, and sends it to the assigned API, resulting in yet another few tables that get filled.
The “Object Links” is the “raw data”, the links between objects. So that’s basically what the PowerShell script was able to find out. But while uploading this data, the app also fills the “Module Links. And it speaks for itself: this is the really interesting table that you want to analyze..
Step 4: Analyze dependencies per module
To look at a bunch of data in a table is hard. Since we’re talking about “links”, why not use “graphviz” to visualize what we have. And that’s exactly what we did – we used this tool: http://www.webgraphviz.com/ . A very simple way to show a (dependency) graph – by easily create a bunch of text that can be copied in this online tool. And that’s exactly what we can do now. With the action “Show Full Graphiz”, it shows a message. Just copy this message to the webgraphiz tool, and you’ll have a visual representation of the interdependencies of all modules of your product. Like we did:

Step 5: Solve circular dependencies
You might ask “what are circular dependencies. Well – easy: just imagine there are a bunch of dependencies, but they make a circle. Like:
- A depends on B
- B depends on C
- C depends on A
Or in even with more:
Well – if you have a big monolith, with a bunch of modules with a lot of interdependencies, your graph may look like I showed above – and all these red arrows, basically indicate “you have work to do”.
You can solve these interdependencies by either “not implementing modules anymore” (you can simply do that by toggling the ignore (action)), or start to combine modules if you realize it doesn’t make sense to split functionalities in modules. In any case: you can’t implement modules that are circularly dependent.
Step 6: manually create App-layer
Once you solved all dependencies, you might want to decide to combine multiple modules in a set of apps.
Now, this step is obviously not mandatory – if you want to create a separate app for all your modules – please do. Honestly, I wish I could turn back the time and had done that. Or at least went a bit more extreme … but we didn’t .. We couldn’t image at the point having to maintain all those modules (+80) as apps. So we continued analysis by simply creating an app-layer, and starting to assign modules to apps. So, simply create a record for each app in the “Apps”-table, and assign an app for each module.
Step 7: Analyze dependencies per app
Now, be careful. Modules can have a decent dependency-flow (you solved it in step 5), but once you start combining again, you might end up with circular dependencies again. Just look at this:
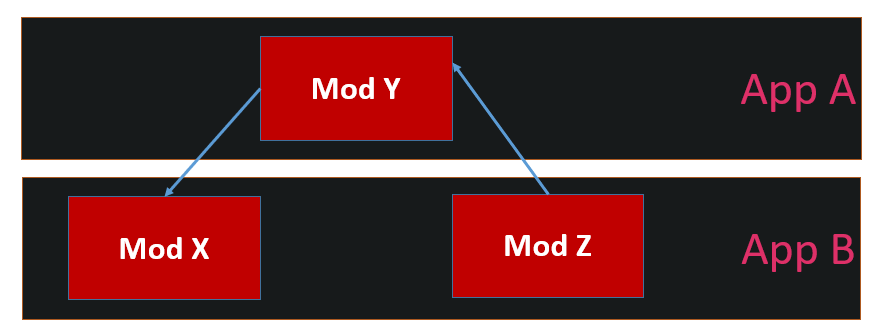
So again, you have this “Get Full Graph Text” action for Apps, which you can use to analyze.
Step 8: Solve circular dependencies
This is the last step! Now you need to solve the circular dependencies again! You can simply do that by combining modules in one app, move modules from app to app, split, or simply again remove modules ;-). You know what I mean – structure your functionality, and come up with an architecture that is possible as a combination of AL Apps.
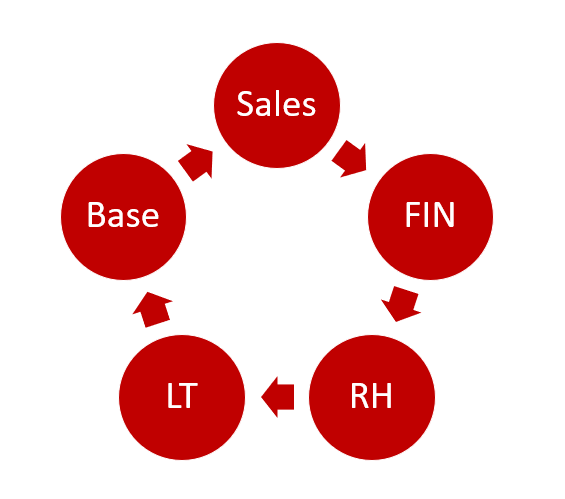
We ended up with this:
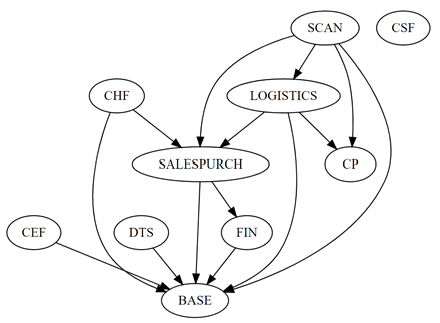
And again – I wish I went a little bit more extreme on the “BASE” app – that would have helped us a lot more with new apps, that could use a part of the BASE app, but not all .. .
Anyway – for you to decide.
Conclusion
Look at this blogpost/solution as a way to get a good, mental picture on the monolith you might have in C/AL .. . Or as one way to have a complete picture on it. And when you have – it’s going to be so much easier to make decisions regarding dependencies .. or things to ignore .. or .. .
Disclaimer
Do NOT judge my code, please. It has been developed because we needed a tool, quickly, for one time only – not to be sold, not to be used for anything else. I just decided to share it because I noticed that many people were interested.
The tool is there AS IS. I’m not going to support, nor update it. Any contributions are always welcome, of course ;-).
Enjoy!
3 comments
3 pings
Impressive, thanks for the post!
Thanks for sharing. Great Post again.
Have you ever considered to put in results from a Delta File creation? I don’t know how well your developers did the job in tagging objects in the Std. Range….Or just due to merges that did not had your versionlist fixing tool… So I was just thinking: If I would create delta files i could put in an indicator into the ALDA Tables that makes it clearly visible “there is something” to consider…maybe import the delta such that its all on one tool to make a decision to what module the changes belong…
Author
Well that would make all the sense in the world. Luckily we already encapsulated it really well – and I wouldn’t have known how to create the deltas for different “modules” from one object anyway, except for when they already would have been in some kind of source control .. .
[…] analysis, where we basically created a GraphVis representation of our C/AL Code .. a tool which I shared as well. That was working for C/AL, and I wanted to be able to show a dependency analysis based on the […]
[…] analysis, where we basically created a GraphVis representation of our C/AL Code .. a tool which I shared as well. That was working for C/AL, and I wanted to be able to show a dependency analysis based on the […]
[…] analysis, where we basically created a GraphVis representation of our C/AL Code .. a tool which I shared as well. That was working for C/AL, and I wanted to be able to show a dependency analysis based on the […]