
A while ago (in fact: in July last year), I posted a blog post about the challenges when “working in Team on apps“. Since then, I have been asked to work on a follow-up post on how we are tackling these challenges in our company today – and if all the assumptions I made also really work.
Well, here it goes ;-). But please, I’m not going to explain the challenges again – just read my previous blogpost about it, and then continue with this one ;-).
Object Numbers
I hate object numbers, and the fact we still need to use them. The dashboard app that I talked about really works. It has been a very small effort to build something that defines:
- Apps & dependencies
- Modules (or functional areas) within the app
- And manage number ranges for modules.
Here are a few screenshots:
We created a RoleCenter to quickly navigate to the different entities:

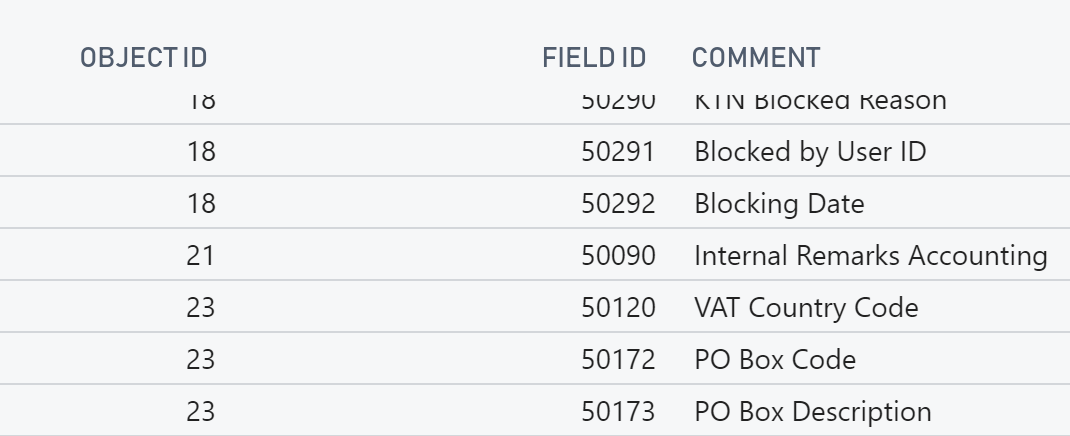
As you see above, we have 2 apps (projects), and 66 modules (functional areas) that is divided over these 2 apps. Each app has as number range:

And within this number range, each module gets its own slimmed down number range:

Before developers start developing, they assign a new number range to its module (functional area) and they are good to go.
It’s a manual thing to do by developers, but this system is simple, and seems to work. We never had any conflicts (yet), because all 7 developers really are disciplined in assigning a number range first, and sticking to it.
Same for field numbers in table extensions: when creating new fields, we basically create them first in this dashboard app, before we actually create it as a field in the app.
During the manual approval of the app (which is also part of the pullrequest-workflow), I specifically look at if we never use object id’s in code (which is a very bad habit of some… ).
Our plan:
At some point, we might create a VSCode extension, that will read from this dashboard app the “next available number for a certain module” to further automate the problem. But this doesn’t have the highest priority at this point ;-).
We would also like to create new code analysis rules that make sure no object id’s are used in code.. .
I also said this in my previous blog:
“We will create a dedicated functionality to “push” our fields from all branches to our dashboard so that we always have a nice up-to-date list to filter and analyse the fields we have at hand ;-).“
Well – we never did and never will, as it works as it is now.. . Fingers crossed.
Planning / Project management
Planning / Project Management is a big part in the methodology. There are a few parameters that really needs to be taken into account:
- Developers should never depend on other developers
- Try to make the least possible merging-conflicts
- Don’t start development, when something you depend on isn’t finished
That’s 3 basic rules we apply for planning our developments, and that basically means that only one developer should work on one functional area.
Remember that only when code is successfully being “integrated” (create a pullrequest to start the merge-process into master), only then your code is available for other developers.. .
Continuous Integration – our branching policy
So, when we know that one developer works on one functional area, we create a branch for this functional area. From whenever the developer is creating that branch, a script will run, and an environment (Database + NST) is being set up specifically for this branch. Since only one developer works against a branch, he will be working with this environment to:
- Download symbols
- Publish during development
- Debug
- Test
- …
Until he’s ready with his developments and a pullrequest can be made.
No Docker
It might come as a surprise, but internally, we are not using Docker. We already had quite an advanced system that spins up new environments in minutes, so we actually had no reason to do so.
Don’t get me wrong – I do use Docker for me personally, but that means that I set up a dev environment for myself, and don’t use the automatically set up environment on the central servers. This will never be supported by the company, but if the developer is more comfortable to work like that, he’s more than welcome to do it like that.
Continuous Integration – The Build Process
We set up two build processes:
-
One that automatically is started when a pullrequest is created
- This is the most significant one. Not only will we compile. We will also make sure no breaking changes were made (will explain later), and the dependent apps are still able to compile against the new codebase of this app.
-
In essence:
- Set up new environments to build in
-
Build/compile/create app
- The compile is a strict compile: I want CodeAnalysis-warnings to fail my build process, as it’s important to also meet with (reasonable) code-analysis-rules.
- Publish this app in the build-environment to make sure it all works, and is upgradable
-
One for when the pullrequest was accepted
- The only purpose of this is to build an app-file and add it to the artifacts, because these will be needed when we will start a release-pipeline …
Continuous Deployment – our release policy
When all is finished, the app needs to end up in the test-environment for the consultant to test. But not only the test-environment – also other. This is what we do:
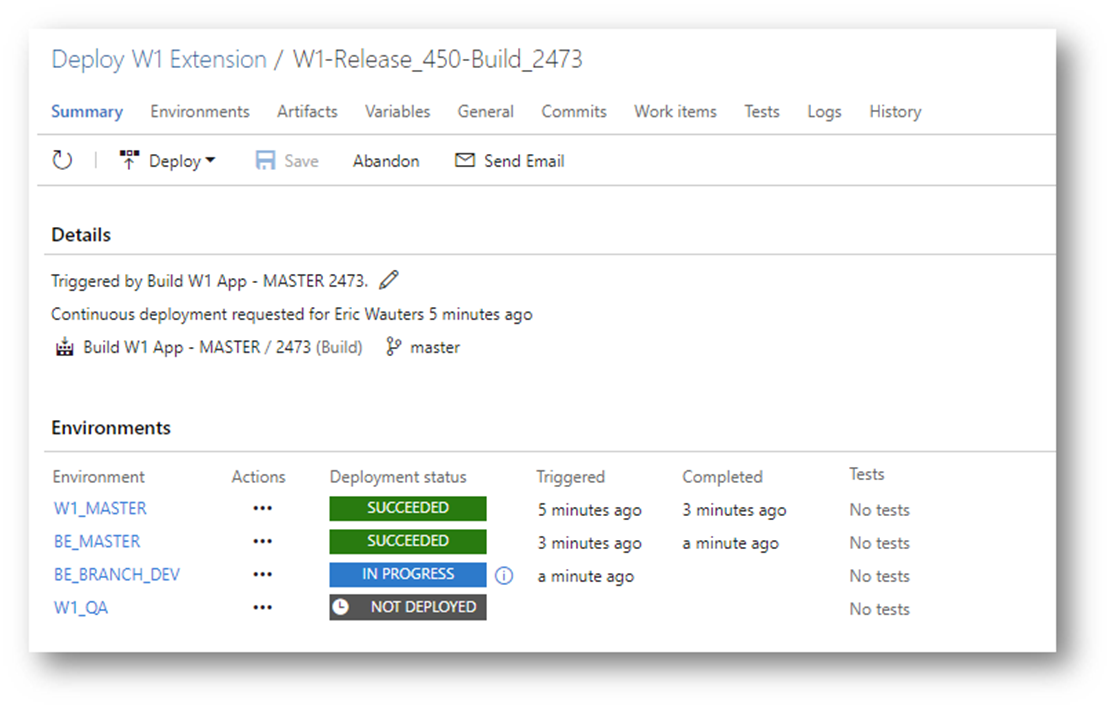
The two master-release-pipelines are there for updating the environments for the build of the app. It will make sure we don’t do breaking changes, and that the upgrade will succeed (if upgraded from previous version.
The branch-release-pipeline is there because this app is an app where another app depends from. So we release this app to all the branch-environments because they are coding against a dependent app, and this way, they can simply update by downloading symbols of this branch.
The QA-release-pipeline is a scheduled one. Every morning, we release the latest version to a test-environment for consultants to test in.
Translations
We don’t translate too much – just before a significant release, we translate by sending the translation file (and memory-file) to lcs.dynamics.com, and review it with the multilingual editor. Both from Microsoft. This process works for us quite well.
On top of that, we decided to put the app-translation-file to .gitignore, because this file is always generated when you compile the app anyway, and causes for conflicts when merging pullrequests. This is now our .gitignore:

Breaking changes
I mentioned in my previous post that we didn’t have a way yet to avoid people from creating breaking changes. Well, we have now. When you look at our build definition:
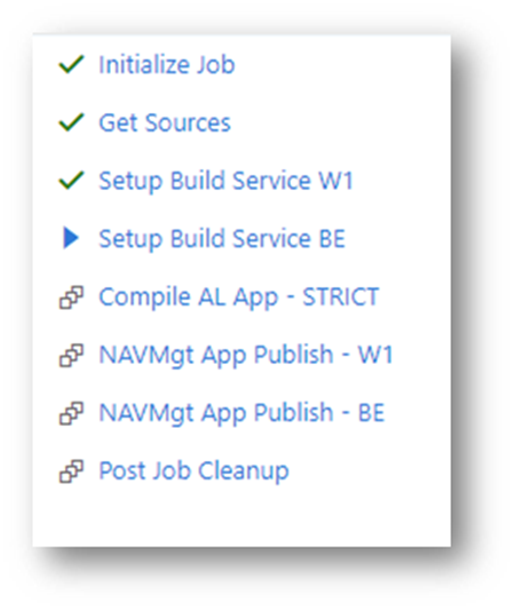
You might wonder why there are a number of services being set up, and a number of publish apps to these services.. . Well, during the build, we set up an environment with the previous app being deployed, and after the compile, we take that result-app, and try to publish and upgrade to it. That should work. And if not, usually it’s because of a breaking change, which is not allowed.
Result: We never had a breaking change, and developers are being notified after a few minutes after they created the pullrequest, and can simply correct the mistake.
We might have to look into this after the Spring release, as Microsoft announced (finally) a possibility to “ForceSync” in the next release.
App Version Number
Another question I get a lot is how we manage the version numbers of the app. Well, quite simple: part manually, part automatically by the build process. As you know, a version number consists of 4 parts. Here they are with some more explanation on how we handle it:
-
Major
- Major release
- any significant new update of the app.
- Is manually set by the dev lead
-
Minor
- Minor release
- Usually when there are breaking changes and we need to be able to code against a certain “previous version number”.. .
- Is manually set by the dev lead
-
Build
- We use this to indicate year and week number
- Automatically set by the build-process (easy with PowerShell)
-
ReVision
- We put the DevOps Build Nr in this part
- Automatically set by the build-process (easy with PowerShell)
This way, we will always have an incrementing number, which is necessary to retain data with an upgrade and such.. . On top of that, all necessary information is there to be very specific in what version/commits/files/… it is by simply looking into DevOps.
Tests
For us, testability is the next thing to work on. Freddy is very much solving the way we can implement testability during a build process, and that’s kind of the thing we were waiting for.. .
Conclusion
We are happy to work the way we work today.
A lot is automated, and the workflow works for us. Sure, this is not only a development-thing (also consultants need to adapt and adopt), but it appears we were able to do just that.
I’m always interested in feedback – so don’t hold back, and put your comments below!
Hope this qualifies as a follow up, and could answer some questions / doubts / .. you had.
6 comments
Skip to comment form
Thanks Waldo to share this with us. I am happy to get another point of view of deploying dev environment (vs docker one) : it’s seems definitively easier to get a full environnement (updated data + code + client + NST) by powershell, than developping new knowledge around docker to get the same result.
Author
Very welcome, and thanks for the confirmation that it actually makes sense 😉
Thanks for this insight, Waldo.
This article helped us built our own environment for our first business central project.
Unfortunately we still have problems on some of the key processes and maybe you can help.
We have reached the point where our developers create pull requests for the first time and thus experience their first merge conflicts. Our current way of resolving those conflicts is to check out to the feature branch and then pull from the release branch. This way all the commits from the release branch will be copied to the release branch, which makes the history confusing. Another problem ist the build In Diff Tool in VS Code, which isn’t really handy.
Do you have any experience on how to handle merge conflicts, how to merge branches and which tool to use?
Author
When we have conflicts, we basically do these steps:
– developer updates the master branch on his local dev
– then merges master to his feature branch – at this point, the same conflicts pop up
– solves the conflicts
– commit & push updates the PR, this time without conflicts
makes sense?
What is that advanced system to spin up development environment?
Author
It’s an internal system where we can create/restore/move/copy/… databases, and craete server instances on any of our internal servers, no matter what version of NAV/BC.. . It’s internal only, so nothing I can share ;-).